Firestore で高負荷なシステムでオートインクリメントIDを採番する方法をここにメモします。(失敗例も含め ...)
負荷テスト1
Firestore にトランザクションを入れて負荷テストを実施してみました。
テスト内容
- 同時接続: 1000
- 同時ユーザ数(最大): 1000
- 1秒間でのユーザ増加数: 10
条件
cloud function
- mem: 2GiB
- cpu: 4
- インスタンあたりの最大同時リクエスト数: 4
- リビジョンのスケーリング(インスタンスの最小数): 1
- リビジョンのスケーリング(インスタンスの最大数): 500
Firestore
- デコレータを使用して、トランザクション内でIDをインクリメント
コード
from google.cloud import firestore # Firestoreクライアントの初期化 db = firestore.Client() # カウンタを格納するドキュメント参照 counter_ref = db.collection('counters').document('counterDoc') def get_next_id(): # トランザクションを使用してIDを安全にインクリメント transaction = db.transaction() @firestore.transactional def increment_counter(transaction): snapshot = counter_ref.get(transaction=transaction) if snapshot.exists: current_count = snapshot.get('count') next_id = current_count + 1 transaction.update(counter_ref, {'count': next_id}) else: next_id = 1 transaction.set(counter_ref, {'count': next_id}) return next_id # IDを取得して返す return increment_counter(transaction) # 次のIDを取得 new_id = get_next_id() print(f"New ID: {new_id}")
結果
簡易的にトランザクションを入れて負荷テストをしたところ、リクエスト数が多すぎて滞留してしまい大量のリクエストタイムアウトが発生してしまいました。
インスタンスのリソースを増強してみましたが、そもそそ Firestore の書き込み部分で滞留していたため別アプローチが必要そうでした。
次の案
Firestoreは、increment オペレーションでのカウンタの実装に便利だったのですが、1 つのドキュメントを更新できる回数は 1秒間に1 回だけのため、同時接続1000を処理しようとすると滞留してしまいます。(その後大量のリクエストタイムアウト...)そのため分散カウンタ(Distributed Counter)という設計があり、今回そちらに変更してテストを行いました。
分散カウンタは、N 個のドキュメントにカウントを分散して持ち、更新時は N 個のうちの1個をランダムで取得してきてカウントを増減させる手法のようです。(実際
のカウント数は、N 個のドキュメントのカウントの合計)
N 個のドキュメントが分散してカウントを持っているので、書き込みスループットは N 倍になるという仕組みのようです。
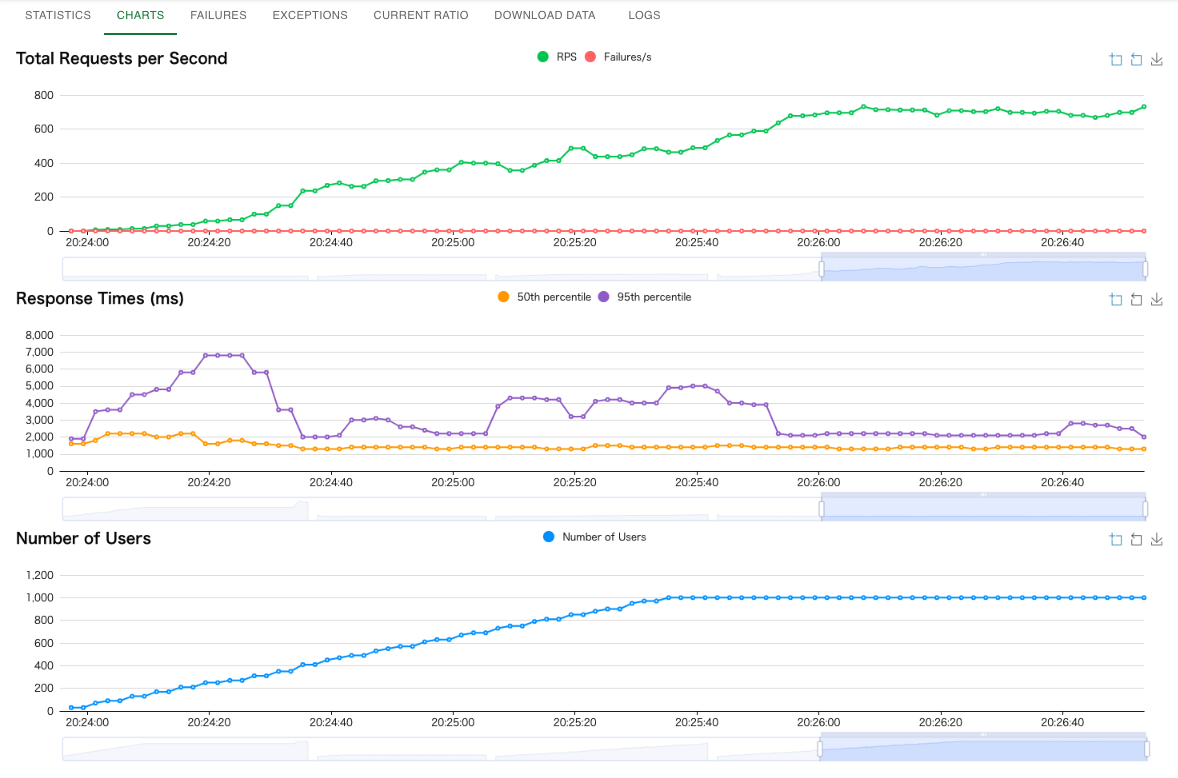
再度負荷テスト2
Firestore で複数のクライアントから同時接続がある場合でも、IDを安全にオートインクリメントするには、分散カウンターのアプローチが有効です。この方法では、複数のカウンターシャード(分割されたカウンター)を作成し、それらの合計を使用して一貫性のあるIDを生成します。
分散カウンターの概念
カウンターシャード
複数のドキュメントにカウントを分散することで、並行処理を効率化し、単一ドキュメントへのアクセス負荷を分散します。
IDの採番
各シャードにランダムにアクセスしてカウントをインクリメントし、すべてのシャードのカウントを合計して次のIDを決定します。
コード
- 初期化: initialize_shards() 関数で、指定した数のシャード(NUM_SHARDS)を作成し、それぞれのカウントを0に設定します。この処理はシステムの初期化時に1回だけ実行すればOKです。
- インクリメント: increment_counter() 関数でランダムにシャードを選択し、そのカウントをインクリメントします。firestore.Increment(1) を使用することで、同時アクセスでも安全にインクリメントができます。
- 合計カウント: get_total_count() 関数で、すべてのシャードのカウントを合計し、現在のカウンター値を取得します。
import random from google.cloud import firestore # Firestoreクライアントの初期化 db = firestore.Client() # 分散カウンターのシャード数 NUM_SHARDS = 10 # シャードコレクションの初期化 def initialize_shards(): for shard_id in range(NUM_SHARDS): shard_ref = db.collection('counterShards').document(str(shard_id)) shard_ref.set({'count': 0}) # カウンターをインクリメントする def increment_counter(): # ランダムなシャードを選択 shard_id = random.randint(0, NUM_SHARDS - 1) shard_ref = db.collection('counterShards').document(str(shard_id)) # シャード内でカウントをインクリメント shard_ref.update({'count': firestore.Increment(1)}) # 合計カウントを取得する def get_total_count(): total_count = 0 shards = db.collection('counterShards').stream() for shard in shards: total_count += shard.to_dict().get('count', 0) return total_count # 初期化(最初に一度だけ実行) # initialize_shards() # カウンターをインクリメント increment_counter() # 現在の合計カウントを取得 total_count = get_total_count() print(f"Total Count: {total_count}")
テスト内容
- 同時接続: 1000
- 同時ユーザ数(最大): 1000
- 1秒間でのユーザ増加数: 10
条件
cloud function
- mem: 2GiB
- cpu: 4
- インスタンあたりの最大同時リクエスト数: 4
- リビジョンのスケーリング(インスタンスの最小数): 1
- リビジョンのスケーリング(インスタンスの最大数): 500
Firestore
- 分散カウンタ(シャード数): 50
想定
- cpuをフルに稼働させるには同時リクエスト数とcpuを合わせるといいのかも...
- 1インスタンスあたり4つの同時リクエストを担当すると、インスタンスの最大数が500あれば2000同時接続も耐えられる予定
- 分散カウンタのシャード数を50に設定(根拠はなし)
結果
- cpuの個数以上にインスタンあたりの最大同時リクエスト数を設定してしまうと、リクエスト待ちになり、その後タイムアウトが発生してしまう。
- cpuの個数とインスタンあたりの最大同時リクエスト数を同じにすると滞留がなくなる
- 上記の設定であれば同時接続1000は処理可能
- スケーリングされるとその部分が一時的に遅くなる(チャートから考察)
- 分散カウンタの最適な数はもう少し調査が必要